
Projekt
SWR
Die Zukunft des Öffentlich-Rechtlichen



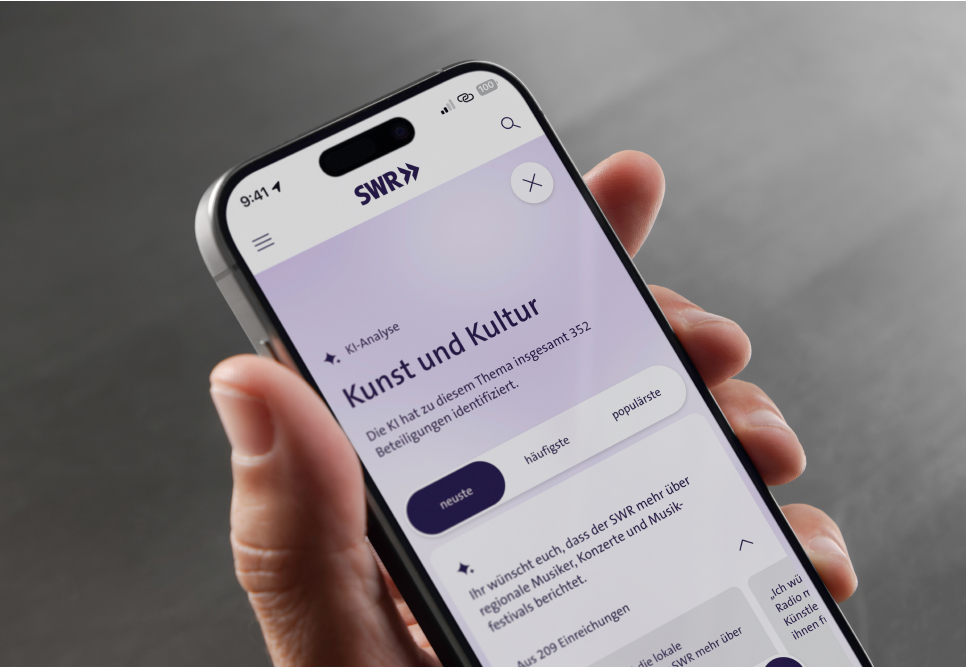



Seit 2020 entwickelt das SWR X Lab in enger Zusammenarbeit mit den Redaktionen digitale Lösungen, die den Wandel im öffentlich-rechtlichen Rundfunk vorantreiben. Wie können Nachrichten die Menschen auf neuen Wegen erreichen? Wie lässt sich das Vertrauen in den öffentlich-rechtlichen Rundfunk weiter stärken? Wie können wir Deutschlands politischen Klimakurs im Blick behalten? Als strategische Innovationsagentur, Impulsgeber und verlängerte Werkbank helfen wir dabei, Antworten auf diese und andere Fragen zu finden. Dabei ist KI längst kein Buzzword mehr, sondern integraler Bestandteil vieler Lösungen – von neuen Interaktionsmöglichkeiten bis zu intelligenterer Ausspielung von Inhalten, Darstellung von Daten und vielem mehr.
Zitat
„Wir wollen heute mutig sein, damit der öffentlich-rechtliche Rundfunk morgen und übermorgen alle erreicht. Manchmal ist das einfacher zu zweit. Daher freuen wir uns, dass denkwerk so inspirierend, partnerschaftlich und professionell mit anpackt und unsere Transformation mit vorantreibt.“
Vanessa Wormer
Head of SWR X Lab
Projekt
SWR
Die Zukunft des Öffentlich-Rechtlichen
Seit 2020 entwickelt das SWR X Lab in enger Zusammenarbeit mit den Redaktionen digitale Lösungen, die den Wandel im öffentlich-rechtlichen Rundfunk vorantreiben. Wie können Nachrichten die Menschen auf neuen Wegen erreichen? Wie lässt sich das Vertrauen in den öffentlich-rechtlichen Rundfunk weiter stärken? Wie können wir Deutschlands politischen Klimakurs im Blick behalten? Als strategische Innovationsagentur, Impulsgeber und verlängerte Werkbank helfen wir dabei, Antworten auf diese und andere Fragen zu finden. Dabei ist KI längst kein Buzzword mehr, sondern integraler Bestandteil vieler Lösungen – von neuen Interaktionsmöglichkeiten bis zu intelligenterer Ausspielung von Inhalten, Darstellung von Daten und vielem mehr.
Zitat
„Wir wollen heute mutig sein, damit der öffentlich-rechtliche Rundfunk morgen und übermorgen alle erreicht. Manchmal ist das einfacher zu zweit. Daher freuen wir uns, dass denkwerk so inspirierend, partnerschaftlich und professionell mit anpackt und unsere Transformation mit vorantreibt.“
Vanessa Wormer
Head of SWR X Lab
Weitere Kunden
Weitere Kunden
Die Fakten
91%
91 % der Fortune 100-Unternehmen erhöhen ihre Investments in KI.
97%
97 % der mobilen Nutzer:innen chatten bereits mit KI Bots.
15,7
15,7 Bill. US-$ wird KI bis 2035 zur globalen Ökonomie beitragen.
Die Fakten
91%
91 % der Fortune 100-Unternehmen erhöhen ihre Investments in KI.
97%
97 % der mobilen Nutzer:innen chatten bereits mit KI Bots.
15,7
15,7 Bill. US-$ wird KI bis 2035 zur globalen Ökonomie beitragen.
Die Fakten
91%
91 % der Fortune 100-Unternehmen erhöhen ihre Investments in KI.
97%
97 % der mobilen Nutzer:innen chatten bereits mit KI Bots.
15,7
15,7 Bill. US-$ wird KI bis 2035 zur globalen Ökonomie beitragen.
Unsere Leistungen
Datenstrategie
Nur mit einer gut durchdachten Strategie lässt sich das Potenzial von Daten voll ausschöpfen. Wir unterstützen Unternehmen dabei, ihre Daten effizient zu managen und zu analysieren, sodass sie fundierte Entscheidungen treffen können.
Datenstrategie
Nur mit einer gut durchdachten Strategie lässt sich das Potenzial von Daten voll ausschöpfen. Wir unterstützen Unternehmen dabei, ihre Daten effizient zu managen und zu analysieren, sodass sie fundierte Entscheidungen treffen können.
Datenstrategie
Nur mit einer gut durchdachten Strategie lässt sich das Potenzial von Daten voll ausschöpfen. Wir unterstützen Unternehmen dabei, ihre Daten effizient zu managen und zu analysieren, sodass sie fundierte Entscheidungen treffen können.
Datenstrategie
Nur mit einer gut durchdachten Strategie lässt sich das Potenzial von Daten voll ausschöpfen. Wir unterstützen Unternehmen dabei, ihre Daten effizient zu managen und zu analysieren, sodass sie fundierte Entscheidungen treffen können.
Data-Driven Prozess Management
Der erste Schritt zur Optimierung ist die Erkenntnis, was geändert werden muss. Mit Datenanalysen helfen wir Unternehmen, Schwachstellen in ihren Prozessen zu identifizieren, Prozesse zu optimieren und so die Gesamtleistung zu verbessern.
Data-Driven Prozess Management
Der erste Schritt zur Optimierung ist die Erkenntnis, was geändert werden muss. Mit Datenanalysen helfen wir Unternehmen, Schwachstellen in ihren Prozessen zu identifizieren, Prozesse zu optimieren und so die Gesamtleistung zu verbessern.
Data-Driven Prozess Management
Der erste Schritt zur Optimierung ist die Erkenntnis, was geändert werden muss. Mit Datenanalysen helfen wir Unternehmen, Schwachstellen in ihren Prozessen zu identifizieren, Prozesse zu optimieren und so die Gesamtleistung zu verbessern.
Data-Driven Prozess Management
Der erste Schritt zur Optimierung ist die Erkenntnis, was geändert werden muss. Mit Datenanalysen helfen wir Unternehmen, Schwachstellen in ihren Prozessen zu identifizieren, Prozesse zu optimieren und so die Gesamtleistung zu verbessern.
Maßgeschneiderte KI-Lösungen
Die Stärke von KI liegt in den Überlegungen dahinter. Wir entwickeln maßgeschneiderte KI-Lösungen, indem wir das technologisch Mögliche mit echten Mehrwerten für Nutzer, Unternehmen und darüber hinaus zusammenbringen.
Maßgeschneiderte KI-Lösungen
Die Stärke von KI liegt in den Überlegungen dahinter. Wir entwickeln maßgeschneiderte KI-Lösungen, indem wir das technologisch Mögliche mit echten Mehrwerten für Nutzer, Unternehmen und darüber hinaus zusammenbringen.
Maßgeschneiderte KI-Lösungen
Die Stärke von KI liegt in den Überlegungen dahinter. Wir entwickeln maßgeschneiderte KI-Lösungen, indem wir das technologisch Mögliche mit echten Mehrwerten für Nutzer, Unternehmen und darüber hinaus zusammenbringen.
Maßgeschneiderte KI-Lösungen
Die Stärke von KI liegt in den Überlegungen dahinter. Wir entwickeln maßgeschneiderte KI-Lösungen, indem wir das technologisch Mögliche mit echten Mehrwerten für Nutzer, Unternehmen und darüber hinaus zusammenbringen.
Data Science
Data Science übersetzt Daten in Erkenntnisse. Mit modernsten Methoden und Tools analysieren wir komplexe Datensätze und decken relevante Muster auf, um Unternehmen dabei zu helfen, intelligentere Entscheidungen für die Zukunft zu treffen.
Data Science
Data Science übersetzt Daten in Erkenntnisse. Mit modernsten Methoden und Tools analysieren wir komplexe Datensätze und decken relevante Muster auf, um Unternehmen dabei zu helfen, intelligentere Entscheidungen für die Zukunft zu treffen.
Data Science
Data Science übersetzt Daten in Erkenntnisse. Mit modernsten Methoden und Tools analysieren wir komplexe Datensätze und decken relevante Muster auf, um Unternehmen dabei zu helfen, intelligentere Entscheidungen für die Zukunft zu treffen.
Data Science
Data Science übersetzt Daten in Erkenntnisse. Mit modernsten Methoden und Tools analysieren wir komplexe Datensätze und decken relevante Muster auf, um Unternehmen dabei zu helfen, intelligentere Entscheidungen für die Zukunft zu treffen.
Kontakt
Ready for change?
Wir freuen uns, von Ihnen zu hören.

Ihr Kontakt
Kaan Karaca
Executive Technical Director
Kontakt
Ready for change?
Wir freuen uns, von Ihnen zu hören.
Ihr Kontakt
Kaan Karaca
Executive Technical Director
Kontakt
Ready for change?
Wir freuen uns, von Ihnen zu hören.
Ihr Kontakt
Kaan Karaca
Executive Technical Director
Kontakt
Ready for change?
Wir freuen uns, von Ihnen zu hören.
Ihr Kontakt
Kaan Karaca
Executive Technical Director
Scroll to explore